Summary
We are researching, prototyping, and piloting tools that use generative artificial intelligence (AI) to reduce training barriers and administrative burdens for staff who help people navigate and enroll in public benefits. These staff include caseworkers, call center specialists, community health workers, and other community partners; we call them benefit navigators.
After researching and experimenting with several ways to help benefit navigators, we have been prototyping an AI-powered chatbot for them to use while on the phone with clients. Our goal is to help benefit navigators quickly research and interpret complex program requirements.
The chatbot depends on a large language model (LLM), an artificial intelligence model that can recognize and generate human-like language. The chatbot responds to questions with a generated answer and direct-quote source citations, enabling benefit navigators to get quick information while verifying answers.
In our prototyping, we found that the way we provide reference material to use when generating chatbot responses affected the quality of responses. One approach led to more accurate answers but less helpful source quotes, while the other had the opposite effect. We developed a third approach that combines the best aspects of the first two.
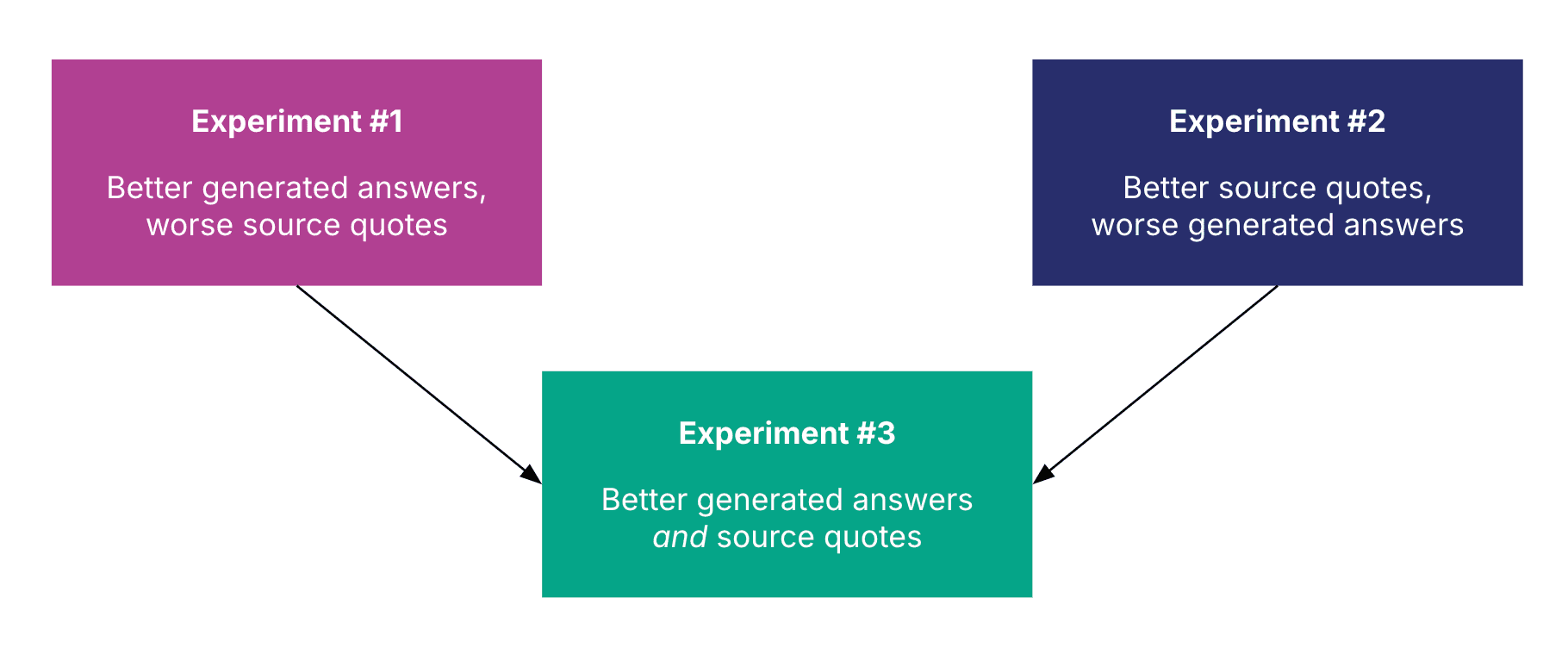
Approach
Generating trustworthy answers
In our user research, benefit navigators told us that they want to know where the chatbot pulls information from. They said if they could verify a response by seeing the exact source text — not just a link to a lengthy document or no citation at all — they’d trust the tool more.
To satisfy this, our chatbot provides two-part responses to benefit navigators’ questions:
An answer to their question, created by generative AI
A direct-quote citation of the original source material used to generate the answer
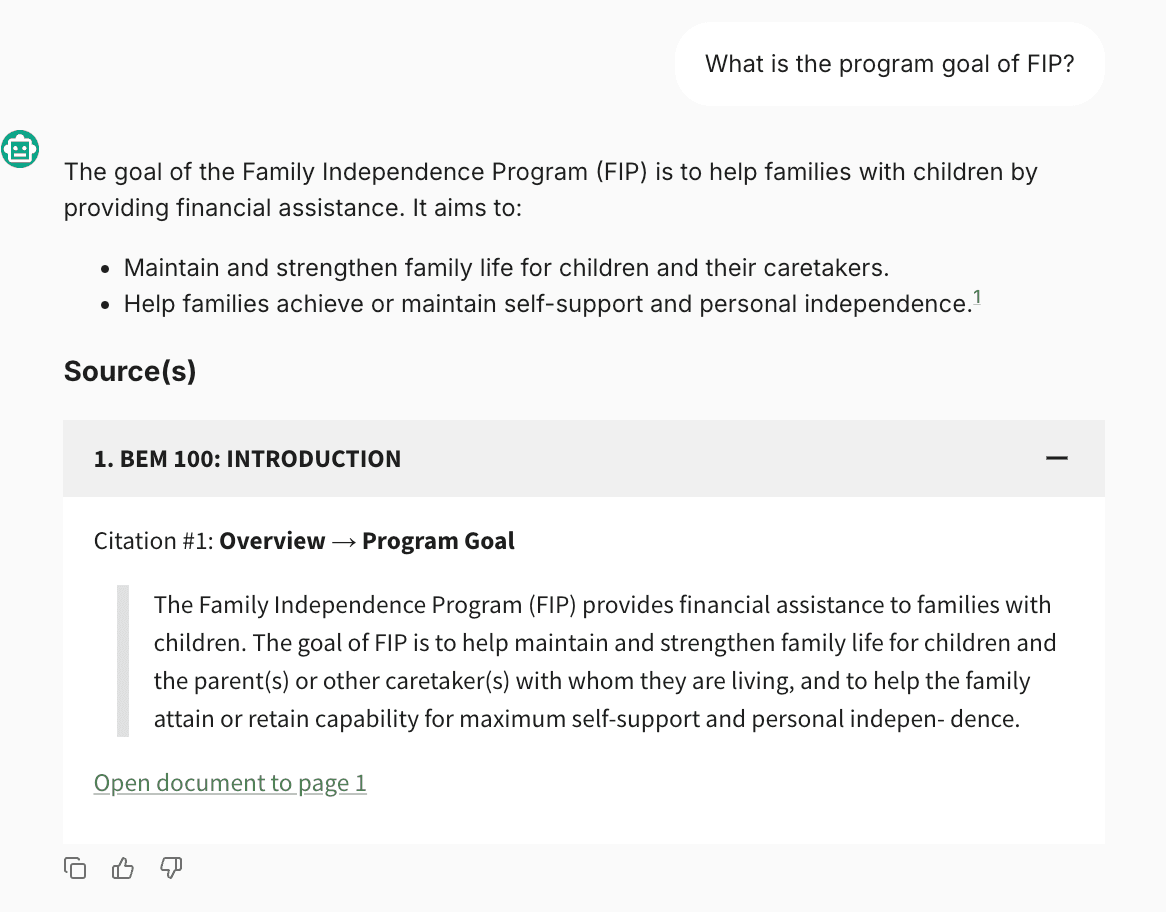
In the example below, a benefit navigator asks “Can college students apply for SNAP [food assistance]?” and receives an AI-generated answer to their question plus a citation from Guru, an internal knowledge base from an organization we partnered with.

A screenshot of the chatbot's response.

A screenshot of the chatbot's citation
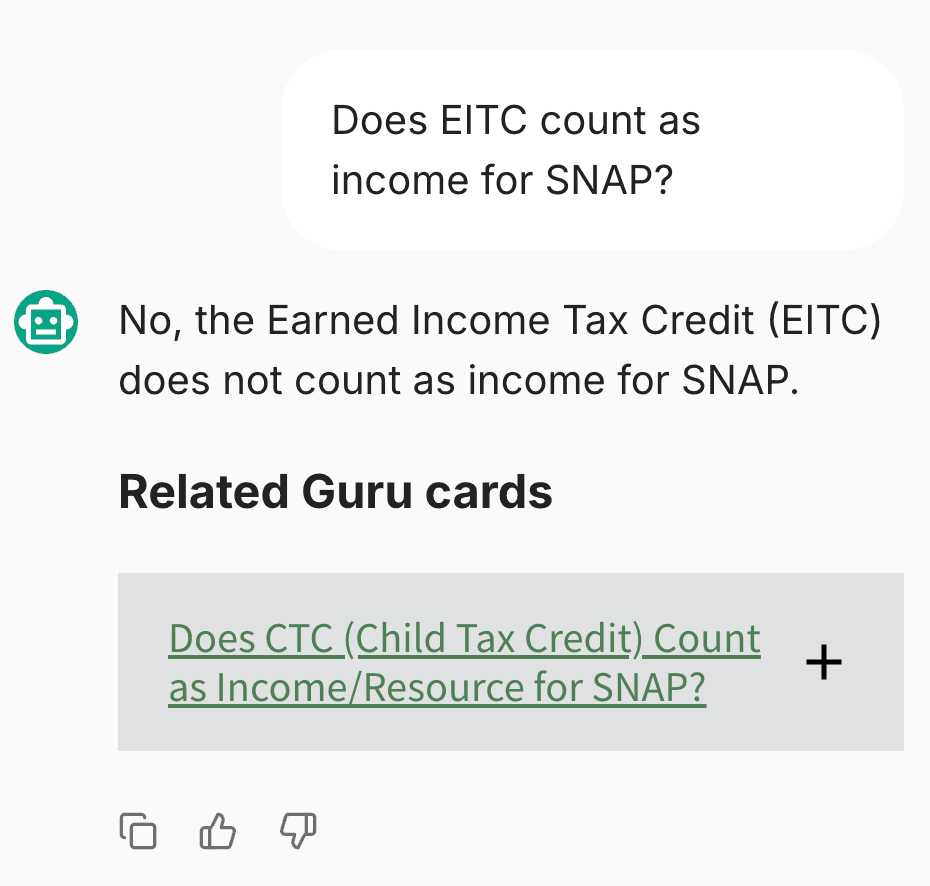
Beyond providing confidence that the chatbot isn’t making up information, direct-quote citations enable navigators to more easily note if the chatbot pulled from the wrong source. In the example below, a navigator asks the chatbot about the Earned Income Tax Credit (EITC); the chatbot responds about the EITC, but the navigator can see that its source was actually information about the Child Tax Credit—a different program:
Benefit navigators speak with people in real time and thus need quick answers. One told us: “We only have two minutes at a time to put people on hold. Sometimes if you ask them to hold again, they say ‘never mind.’ The shorter the answer, the simpler the words are, the better.” So our challenge is to create a chatbot whose answers are relevant, accurate, trustworthy, and concise.
Breaking down source data into manageable chunks
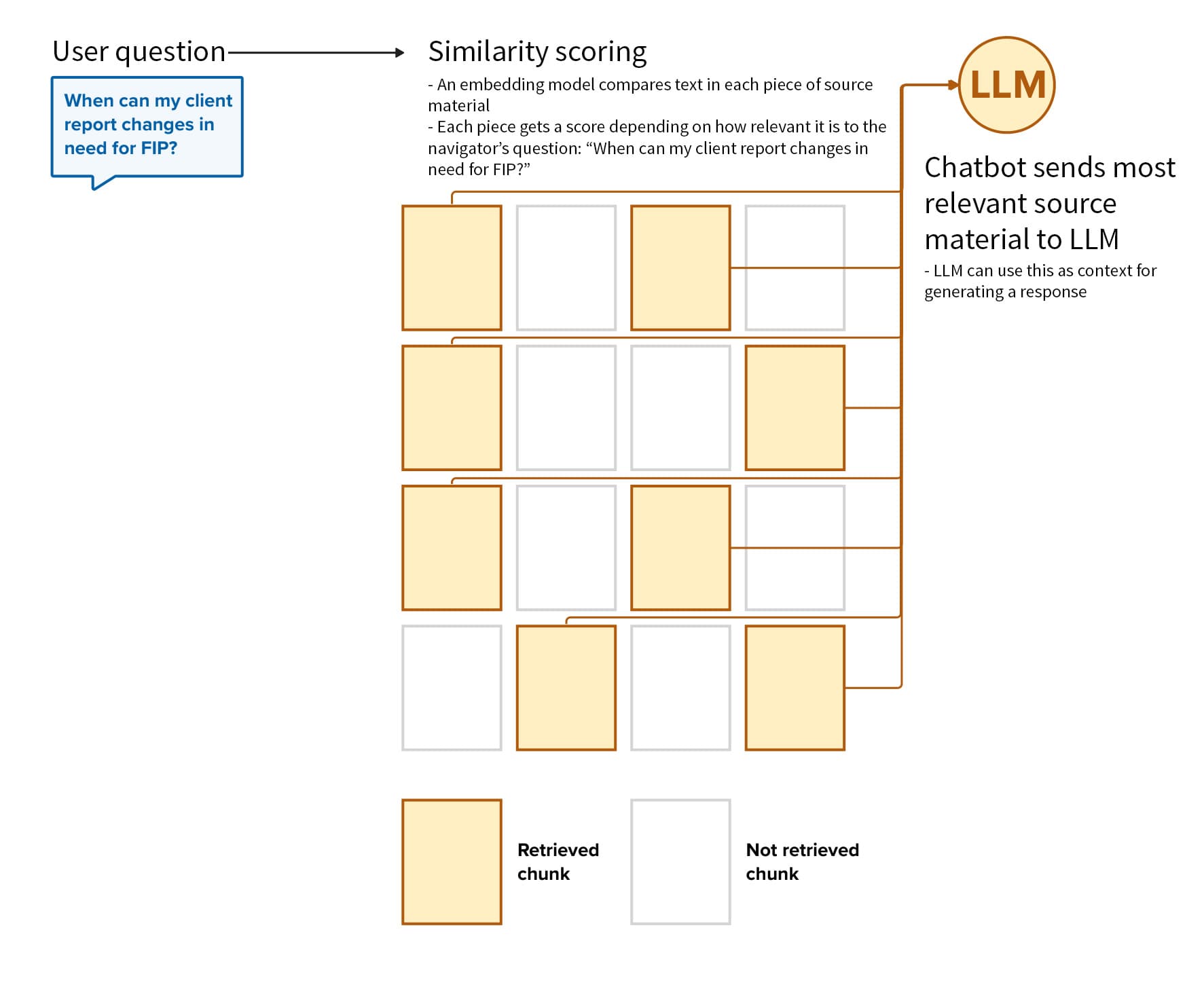
Our chatbot pulls from a large amount of data when answering navigators’ questions. This can include massive documents, such as a policy manual with over 1,000 pages. Here’s what happens:
A navigator asks the chatbot a question.
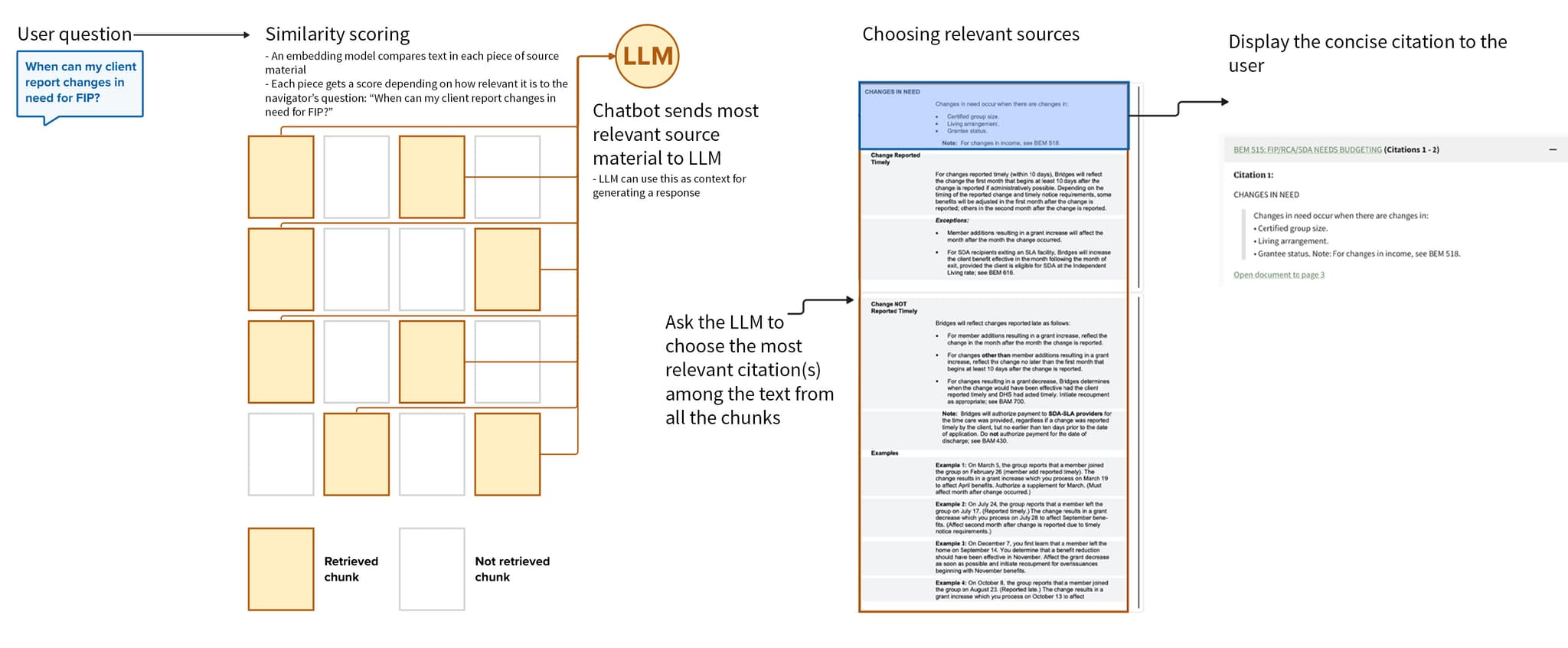
An embedding model — an AI model that can identify semantic meaning in text — then compares the text in each piece of source material, with each piece getting a score representing how relevant it is to the navigator’s question.
The chatbot sends the most relevant source material to the LLM for processing and generating an answer to the question.
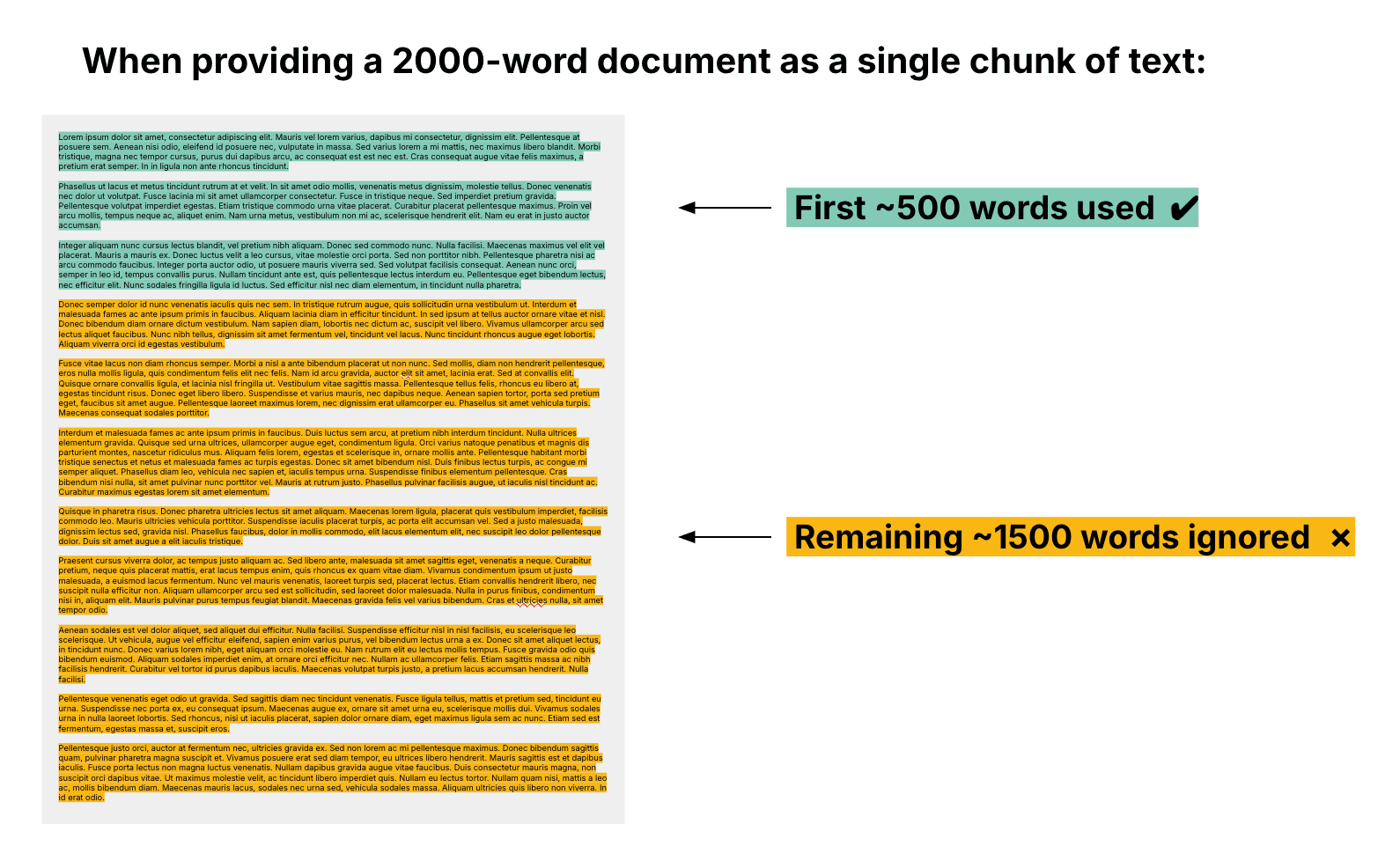
But there’s a catch: the embedding model that we use to compare the similarity of text (in step #2) can only take ~500 words of input text. If we give it a longer amount, it ignores everything after the first ~500 words.
To ensure that the embedding model uses the full document, we split up large amounts of text data into smaller “chunks.” Then, instead of comparing a question to each source document’s full text, the embedding model compares the question to each chunk of each document.

There are many methods of converting large amounts of text into smaller chunks. Here are a few types of chunks that one might create:
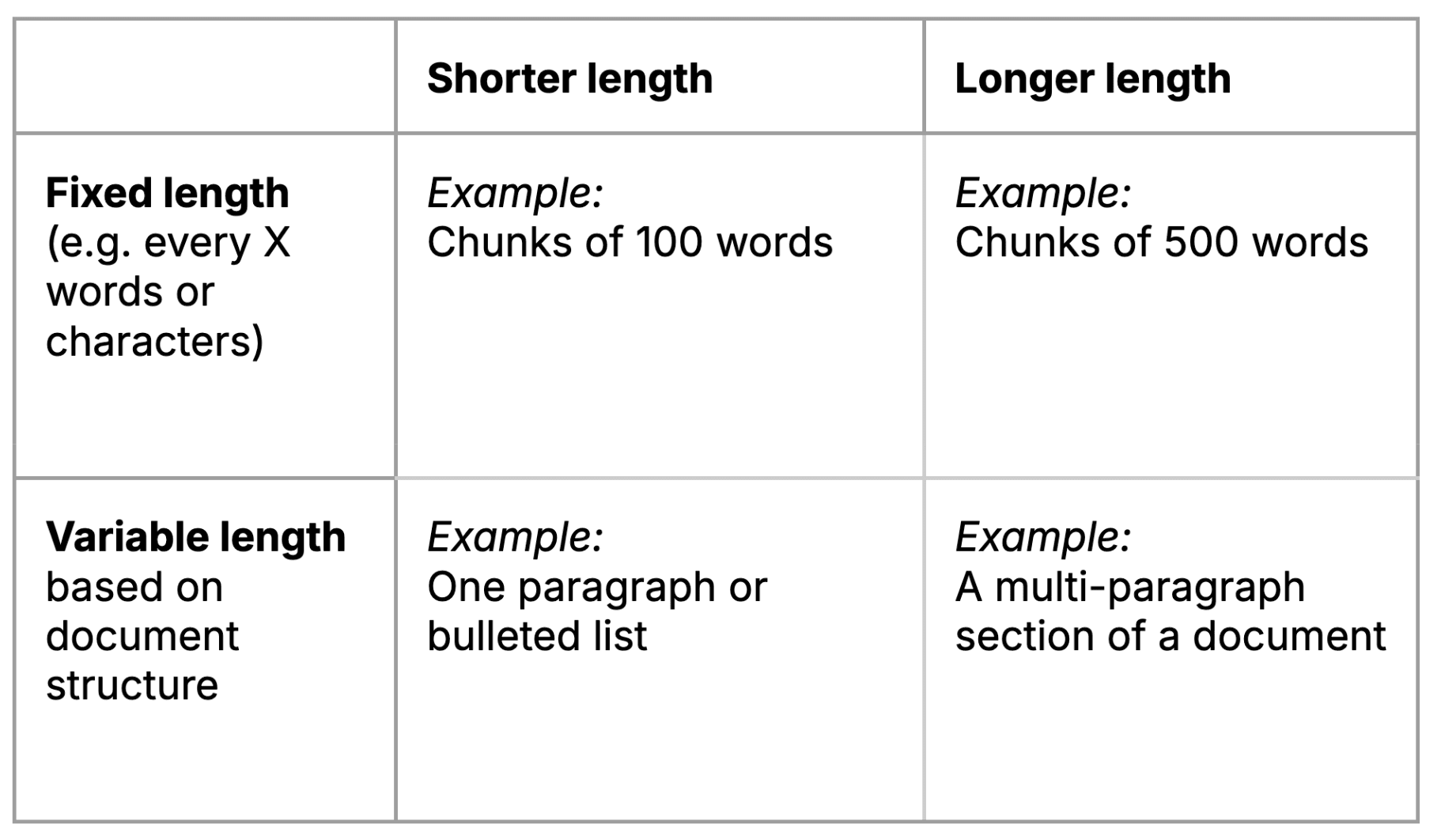
Different chunking methods have advantages and disadvantages for the chatbot results they produce — as we saw in our experiments.
Experiment 1: Easy LLM implementation, but difficulty for human understanding
Our initial approach to chunking focused on easy implementation by using fixed-length chunks. We used long chunks of around 500 words to provide the LLM with a lot of context for generating responses.
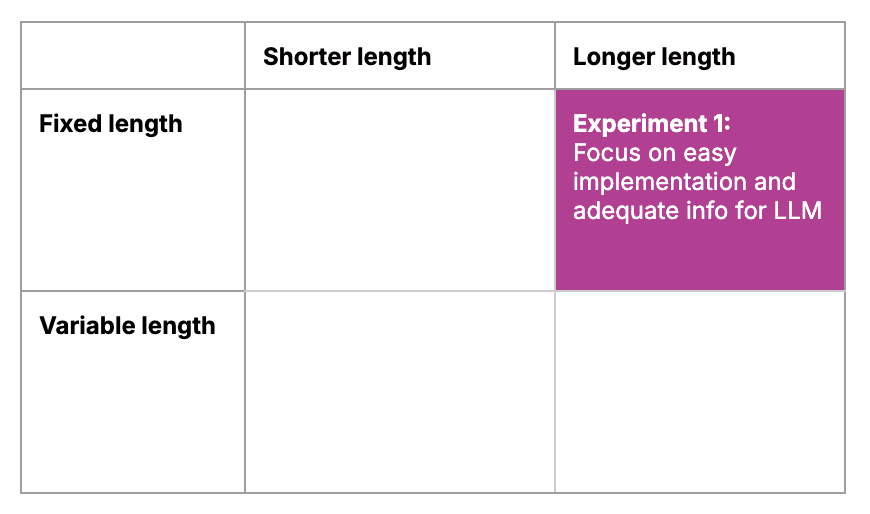
Using these long, fixed-length chunks worked for the LLM but we ran into a problem: providing helpful source citations for humans.
Recall that the chatbot provides two-part responses: a generated answer and a direct-quote citation. For the direct-quote citations, we had the chatbot display the same chunks of source text that the LLM used to generate the summarized answer. The chunks looked like this:

So the chatbot’s direct-quote citations looked like this:

Citations in the form of long chunks made it difficult for humans to read and understand, because:
The fixed length of chunks meant that they might start in the middle of one paragraph or section and end in the middle of another, combining multiple topics into a single chunk and/or splitting a single topic across multiple chunks.
The long length made it difficult for people to find the most relevant information within the chunk. This was a problem because benefit navigators are using the chatbot while on the phone with clients and don’t have time to wade through large volumes of text.
So we continued experimenting.
Experiment 2: Better citations, but worse LLM performance and response quality
To help provide benefit navigators with better citations, we experimented with paragraph-based chunking that captured complete paragraphs or bulleted lists. This method resulted in chunks that were variable in length but shorter on average.
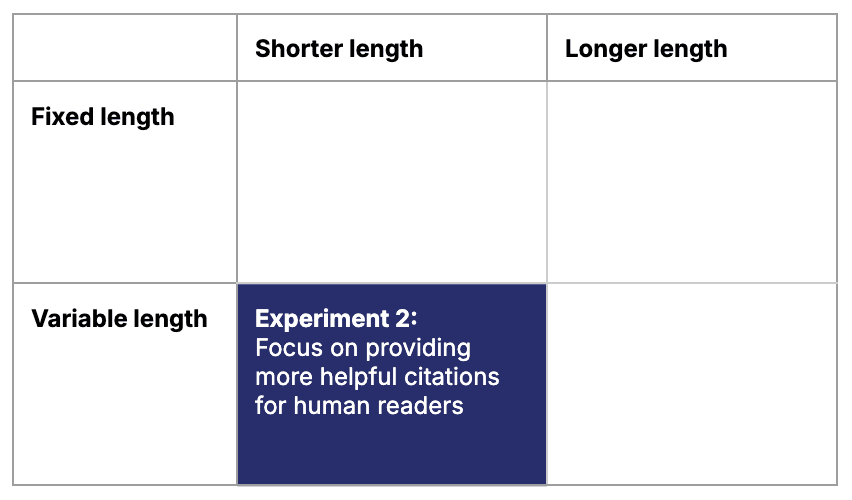
These paragraph chunks made the direct-quote citations easier for humans to read and understand.

A screenshot of a document split into chunks by paragraph.
A screenshot of the chatbot's citation.
Unfortunately, shorter chunk length led to worse LLM performance. The reduced surrounding context for each chunk meant that:
It was harder for the LLM to accurately select the most relevant chunks to use for generating the answers.
After selecting chunks, generating the answers was harder for the LLM.
We continued our quest to strike a balance between the quality of generated answers and the readability of direct-quote citations.
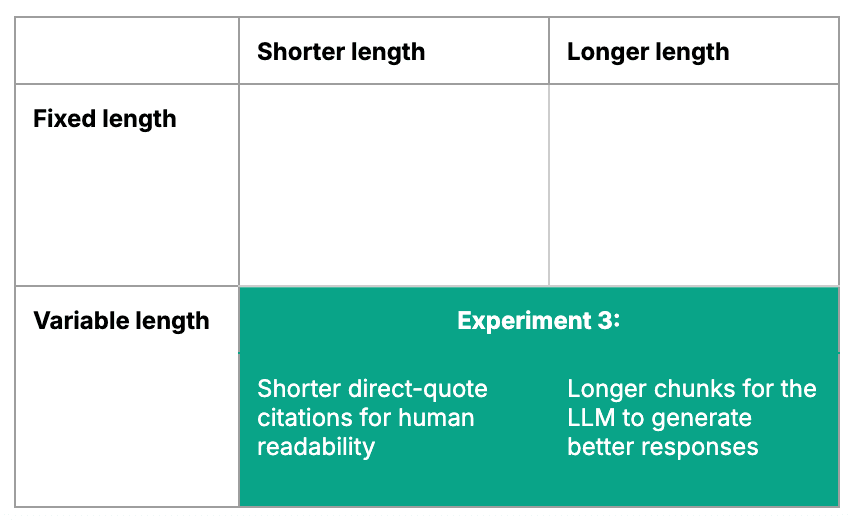
Experiment 3: Improving citations and generated answers
Seeking to capture the best of both approaches, we tried another method using a key insight: the chatbot does not have to provide the entire raw text chunk as a direct-quote citation. Rather, it can provide the most important information from the raw text chunk as a direct-quote citation.
For this hybrid approach, we split the text into longer chunks — which we then split into paragraph-long “sub-chunks.”
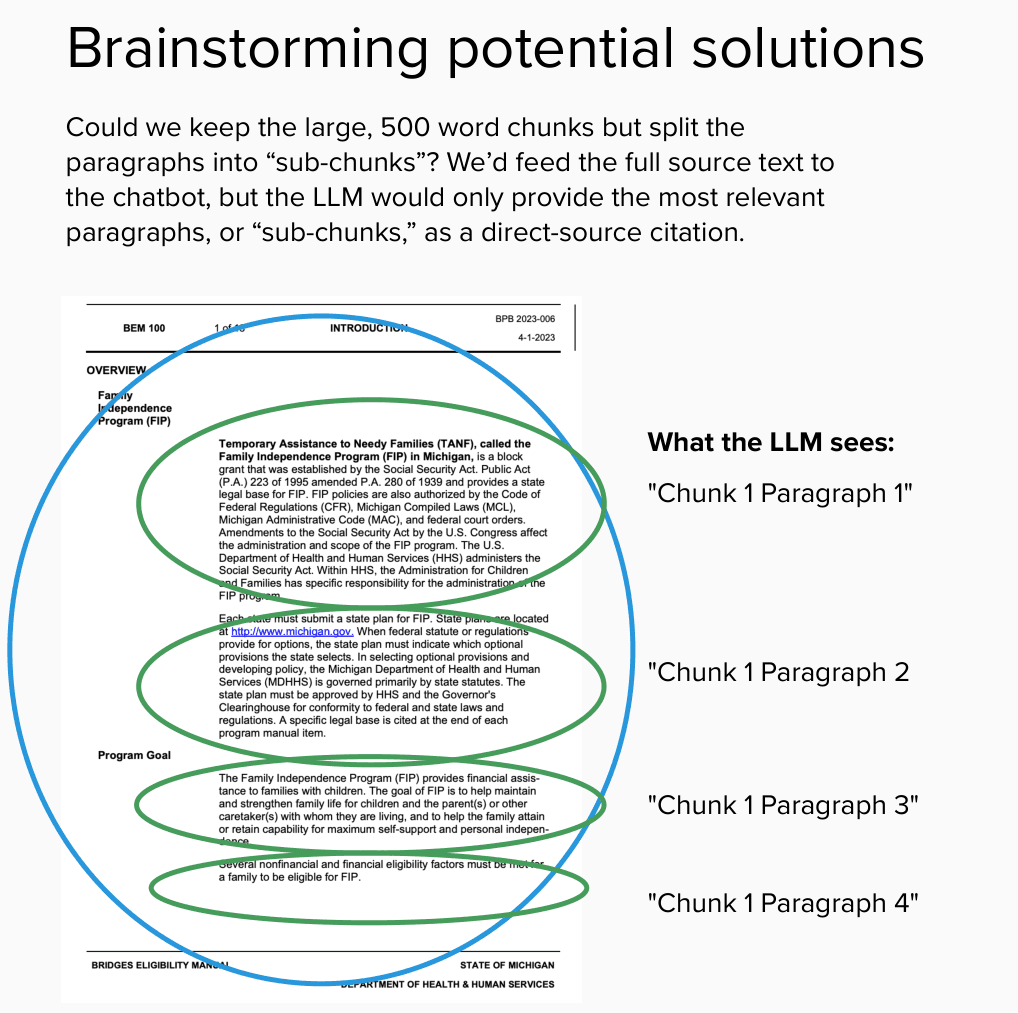
We sent the longer chunks to the LLM to generate an answer. But for the direct-quote citations, we asked the LLM to evaluate which of the paragraph-long “sub-chunks” were most relevant, and to only display those.
This provided us with the best of both worlds:
Answer generation: The longer chunks gave the LLM more context — helping it do a better job of retrieving the most relevant chunks and generating a better answer.
Citations: Only providing certain paragraphs as the direct-quote citations prevented benefit navigators from being overwhelmed with large amounts of text.
Also note that we generated the longer chunks by analyzing the document structure for section headings and pulling cohesive sections of source material rather than pulling arbitrary, fixed-length chunks as in Experiment 1.
We made further improvements to the chunking as well. When sending the text chunks to the LLM we incorporated metadata, such as adding all the parent document headings associated with the chunk or adding a summary of preceding paragraphs. This helps to ensure that the LLM interprets the chunks with even more context.
Conclusion
Through our prototyping process, we experimented with a progression of three approaches to breaking source reference material into chunks, which we then passed to our LLM in order to create chatbot answers.

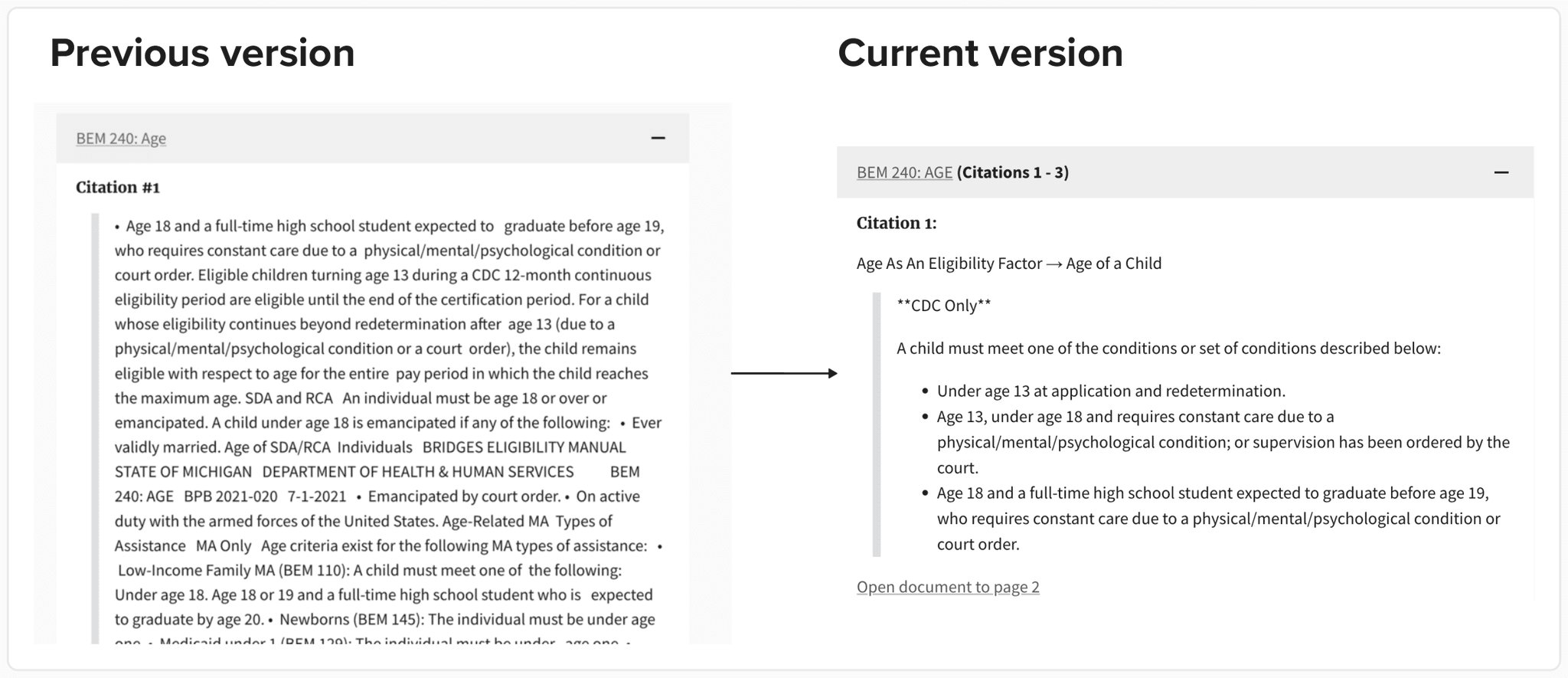
Our third, hybrid approach helped the LLM generate high-quality answers and readable direct-quote citations.
The change in direct-quote citations from Experiment 1 to Experiment 3 is particularly noticeable:
While this may just seem like an interesting technical problem to explore, these iterative experiments are ultimately in service of improving benefit navigators’ ability to help people access public benefits.
Our team continues to improve the chatbot in a range of ways. In this project, we are publicly sharing our learnings as we progress through prototyping and piloting. To learn more, check out the recordings from our demo days on our user research and early experimentation.
Special thanks to Alicia Benish and Martelle Esposito who contributed to this article.
Written by

Senior consultant

Designer/researcher

Senior software engineer
