

As tools powered by artificial intelligence (AI) become more widespread in government, it’s crucial for government agencies and other stakeholders to know how to make content machine-readable, or easy for a computer to read and process. Thoughtfully designed content can empower large language models (LLMs) — AI models that can recognize and generate human-like language — to deliver accurate and relevant outputs.
Importantly, making your content AI-friendly can also increase its accessibility, readability, and skimmability for humans, including those who use assistive technology.
Maintaining best practices for machine readability and content design can help you if:
You’re an agency staffer or administrator looking to use AI to improve operations and service delivery
You’re a policy analyst hoping to use AI to help with policy research, analysis, and drafting
You’re a communications professional or content strategist hoping to make agency information more accessible
In this guide, you'll learn how to select the right file formats and improve content design to enhance LLM performance as well as make information more accessible and useful for human users. Each of these two actions can help on its own, but doing both is especially powerful.
This toolkit can help you:
- Provide an LLM with the best file format to optimize for machine readability
- Improve your content structure and design to help an LLM better understand the information it contains
Note that what follows is a general overview. The details for specific applications, workflows, and contexts can vary.
Tactic 1: selecting the best file format
Some file formats are significantly more machine-readable than others. That’s because of the steps a computer needs to go through to “understand” a document.
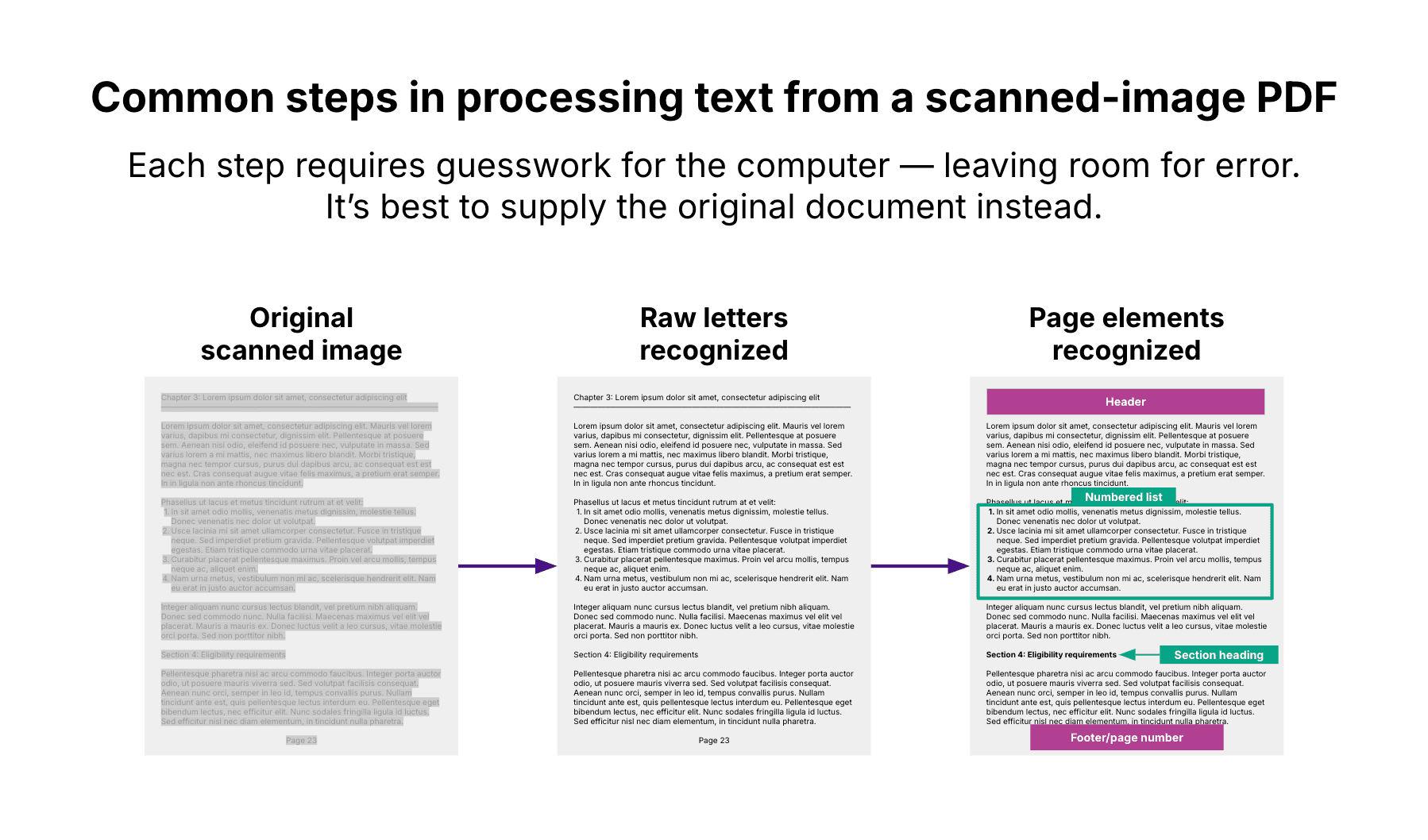
Imagine you scan a printed document, creating a PDF, JPG, or PNG. While a human would see a neatly organized document with an intuitive structure, a computer might see a disorganized stream of text:

A computer must go through several steps to fully process the document’s information, each leaving room for error:
Recognizing letters in the image: Optical character recognition is when a computer tries to extract text from a picture of text. Depending on the image quality and the font used, a computer may mistake some characters for others — such as a capital I for a lowercase L (“l”) or a letter O for a number zero (0).
Understanding document structure: After recognizing the individual letters on a page, the computer must differentiate between components on the page — such as page headers and footers, columns, tables, bulleted and numbered lists, headings and subheadings, paragraphs, and image captions. Having a rich understanding of the page elements, rather than seeing just a continuous stream of text, is critical for fully making sense of its contents. But this is a very challenging task for computers, and the results can be a mess. You may have experienced this if you have ever copied text from a PDF or image to a text document. This can result in losing the document’s original formatting and the arrangement of tables, lists, captions, and other elements.
Exporting a PDF directly from the source document — for example, exporting a PDF from Microsoft Word or Google Docs — can be slightly better than scanning a paper document as one of these file types. This is because it can provide clearer text shapes compared to what you might get from scanning a printed document, leaving less room for error during the step of optical character recognition. Still, it’s not ideal.
Meanwhile, with a file format like HTML, XML, or Markdown, a computer can directly access the text as it was originally written — eliminating the need for optical character recognition and easing the task of understanding page elements. (Less ideal but still better than a PDF is DOCX, or alternatively DOC.)
The technical details of this topic can get complex, but generally, you want to use file formats that are higher on the ladder below, rather than ones that are lower:

Fortunately, in many cases you can simply ask for the source document. If you are part of a government agency or working in partnership with one, it should be easy to get a copy of the source document. Remember: the PDF didn’t appear by magic — someone created it from an original document.
To provide the LLM with as simple of a file as possible, consider exporting as HTML if using Microsoft Word (save as “Web Page, Filtered”) or exporting as a Markdown file if using Google Docs.
Note that for structured data, like what you find in a spreadsheet, it’s best to supply it in a format such as CSV, JSON, or XML — not as a text document.
Recent advances in AI have improved the ability of computers to recognize elements of document structure, but supplying original machine-readable documents remains the better way to provide information.
Tactic 2: optimizing content design
LLMs have a much easier time reading content that is clear, well-structured, and semantically rich.

There are a number of things you can do to make content easier for a computer to understand:
Write using plain language
Use frequent headings to describe sections of the text, and create a clear hierarchy of headings and subheadings
Organize lists of items as bulleted or numbered lists, rather than as a run-on sentence or paragraph
Define key terms, and consider including a glossary
Provide document metadata, which can include information like important dates (when the document was first written, when it was published) and topic tags that describe the content
When creating headings, it’s important to use the “paragraph styles” feature of programs like Microsoft Word or Google Docs, rather than simply making the text larger or bold. This automatically applies a distinctive style to all headings in the document, saving you formatting work. More importantly, if you’re exporting the document in a machine-readable format as discussed above (e.g. HTML, XML, Markdown, DOCX), the file will internally tag the headings as such. This way, a computer reading the document will see them marked as headings and not merely body text that happens to have a different visual appearance.
These are good practices for designing content even if you’re not planning on having an LLM read it. Improving content design can also improve skimmability and accessibility for humans, including for people using screen readers.
For more information on content design, check out this introduction.
Combining both tactics
The tips described above provide two avenues for improving an LLM’s ability to understand your content.
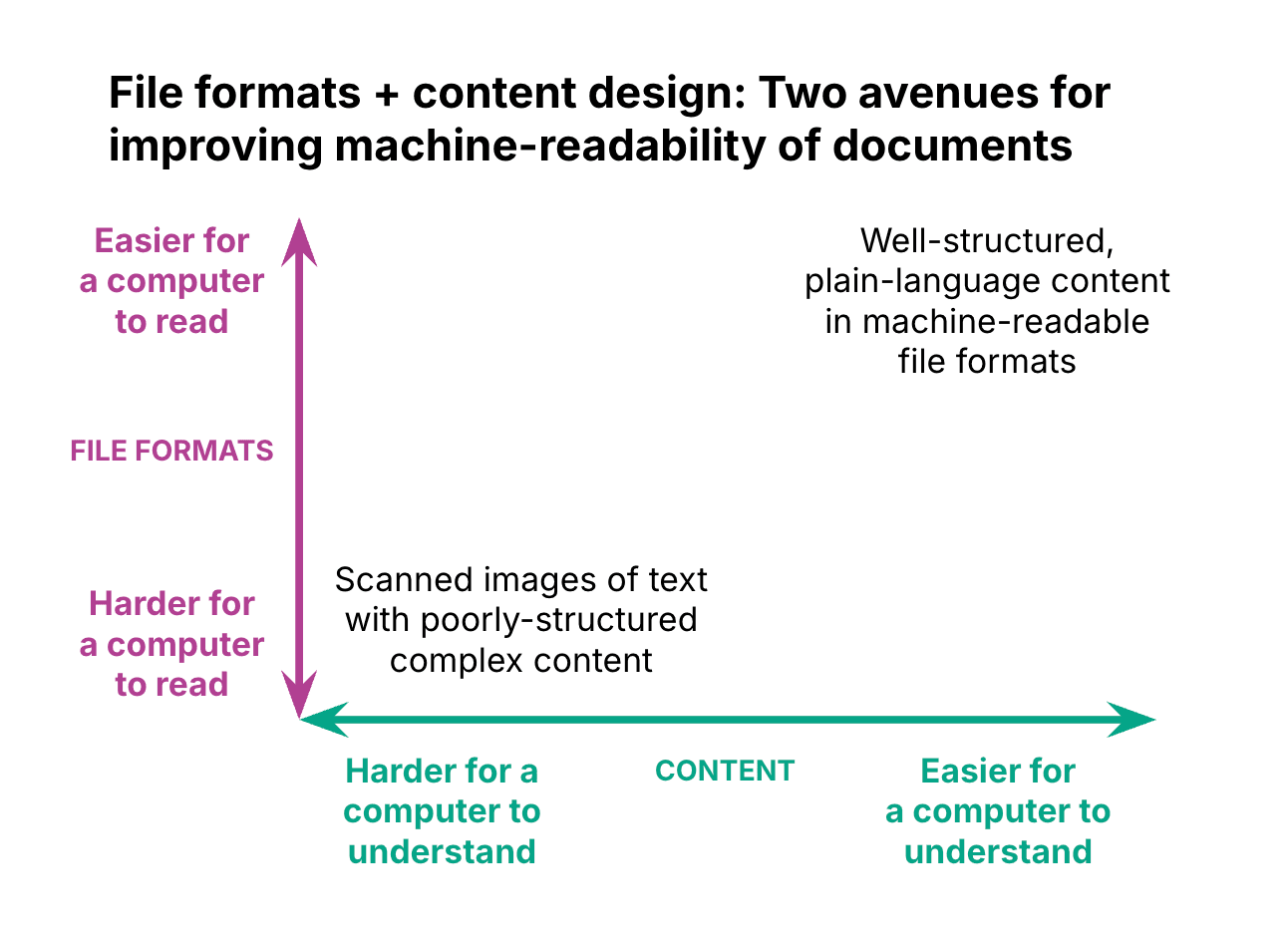
They are most powerful when used together. However, if your team only has capacity to focus on one, it will still help improve your LLM’s output; any step forward is progress. For example, if you are stuck using a document with poor content design, providing an LLM with an open, machine-readable file format will still help it better process the content; perhaps improving the content design can be a future undertaking.
Conclusion
In summary, making content more machine-readable for AI involves providing easy-to-read file formats and optimizing content design:
Good text file formats include HTML, Markdown, and XML, while good formats for structured data include CSV and JSON. Avoid PDFs.
Optimizing content design means using plain language, headings (tagged as such), bulleted and numbered lists, metadata, and definitions of key terms.
This doesn’t have to be an all-or-nothing endeavor. Even small improvements in how you structure and format documents can make a significant difference in how effectively both AI tools and humans are able to understand content.
Starting from what you can implement today — whether it’s adding clear headings, using bulleted or numbered lists, or exporting in a machine-readable file format — can create a great base to build upon as your needs evolve.
Special thanks to Kevin Boyer, Ryan Hansz, Kasmin Scott, and Kira Leadholm for contributing to this article.
Written by

Senior consultant
